In meinem HomeLab spielt der Proxmox Backup Server eine zentrale Rolle. Viele unterschätzen das Thema Backups – aber wenn eine VM plötzlich weg ist oder Hardware ausfällt, sind die Schmerzen groß. Genau deshalb zeige ich dir in diesem Beitrag, wie ich meinen Proxmox Backup Server (PBS) eingerichtet habe: mit ZFS-Mirror, by-id-Passthrough, Backup-Jobs, Remote-Sync und Wiederherstellungsstrategie.
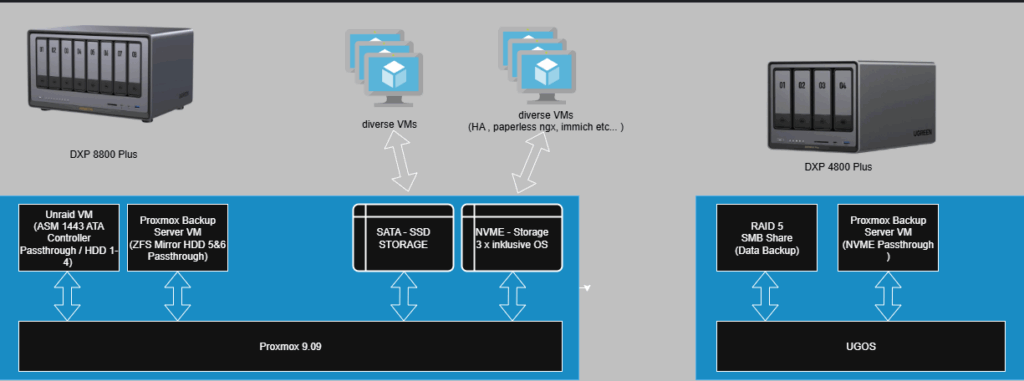
Ich verwende in meinem Setup mehrere UGREEN NAS-Systeme, die hervorragend mit Proxmox harmonieren und gleichzeitig effizient und leise laufen. Meine Geräte:
Bevor wir starten, kurz der wichtigste Unterschied:
ZFS Mirror → schützt mich vor Plattenausfall
Proxmox Backup Server → schützt mich vor Datenverlust
Remote Sync → schützt mich vor Brand, Diebstahl, Defekt
Ich erlebe in der Community häufig, dass ein RAID oder ZFS-Mirror als Backup verstanden wird. Das ist aber nur eine Verfügbarkeitsschicht, kein echtes Backup. Backups entstehen erst, wenn:
Daten inkrementell gespeichert werden
Versionen existieren
sie auf getrennter Hardware liegen
Genau das erfüllt der Proxmox Backup Server im gezeigten Setup.
Mein Setup – Überblick
Ich nutze:
Proxmox 9 auf meinem HomeLab
UGREEN DXP8800 Plus als Haupt-NAS
UGREEN DXP4800 Plus als Backup-NAS
Ein weiterer PBS in der Cloud (optional)
Damit kann ich selbst bei einem kompletten Hardware-Schaden alle Backups wiederherstellen.
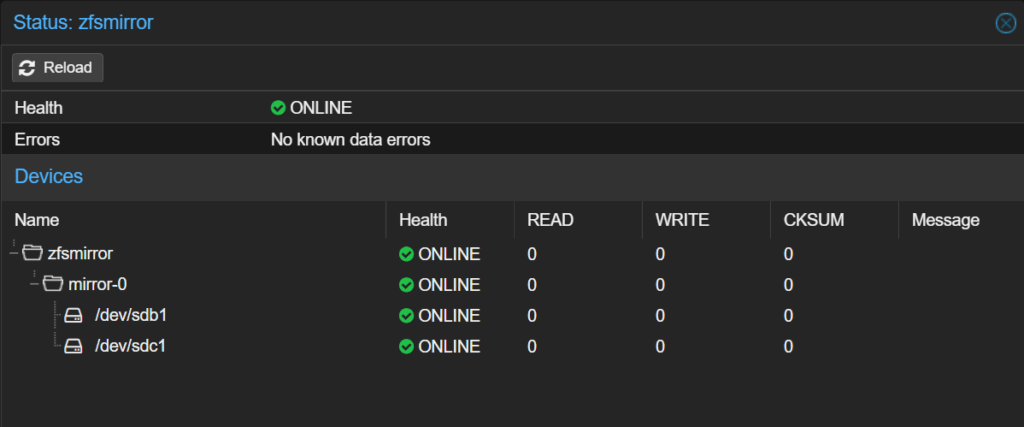
ZFS Mirror anlegen – die Basis
Zuerst habe ich im UGREEN NAS ein ZFS Mirror aus 2 HDDs angelegt. Das schafft Redundanz und optimale Performance für den PBS-Datastore.
Damit ZFS in der PBS-VM funktioniert, brauche ich die echten Laufwerke – und genau dafür ist Passthrough per /dev/disk/by-id unverzichtbar.
Warum ich /dev/disk/by-id nutze
Wenn du einfach /dev/sda oder /dev/sdb durchreichst, kann die Reihenfolge nach einem Reboot oder Update wechseln. Das wäre fatal.
Darum nutze ich:
ls -l /dev/disk/by-id
Dort suche ich meine beiden HDDs heraus – in meinem Fall z. B.:
ata-ST4000DM004_XXXXXX
ata-ST4000DM004_YYYYYY
Diese IDs trage ich später bei der VM als Passthrough ein.
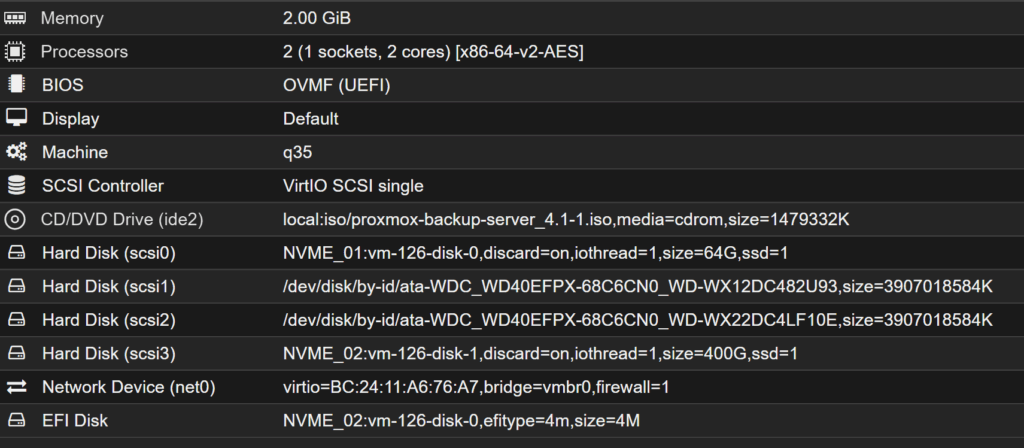
Erste HDD an scsi1:
qm set 126 --scsi1 /dev/disk/by-id/ata-WDC_WD40EFPX-68C6CN0_WD-WX12DC482U93
Zweite HDD an scsi2:
qm set 126 --scsi2 /dev/disk/by-id/ata-WDC_WD40EFPX-68C6CN0_WD-WX22DC4LF10E
Proxmox Backup Server ISO vorbereiten
Ich lade das ISO bei Proxmox herunter und packe es ins in mein Proxmox.
Dann lege ich eine neue VM an:
BIOS: UEFI
Machine: q35
Disk: 64 GB (SSD-Simulation)
RAM: 2 GB
Cores: 2
Netzwerkkarte: VirtIO
Alles sehr genügsam – PBS ist extrem leichtgewichtig.
ZFS Mirror im PBS anlegen
Sobald die VM läuft:
Storage → Disks
Die beiden Passthrough-HDDs auswählen
ZFS → Mirror
Namen vergeben (z. B. zfs-mirror-pbs)
Erstellen
PBS im Proxmox einbinden
Jetzt binde ich den Backup Server in Proxmox ein:
Datacenter → Storage → Add → Proxmox Backup Server
Hier brauche ich:
IP des PBS
Benutzer: root@pam
Datastore-Name (z. B. zfsmirrorpbs)
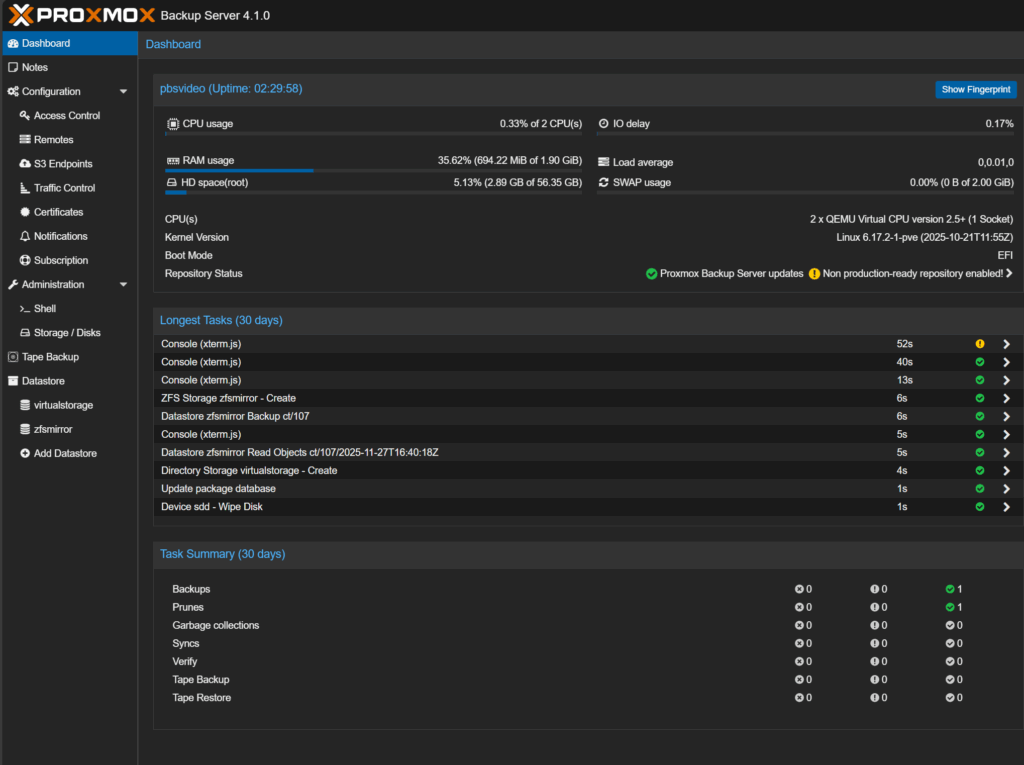
Fingerprint aus PBS → Dashboard → „Show Fingerprint“
Nach dem Speichern erscheint der PBS sofort im Storage-Baum.
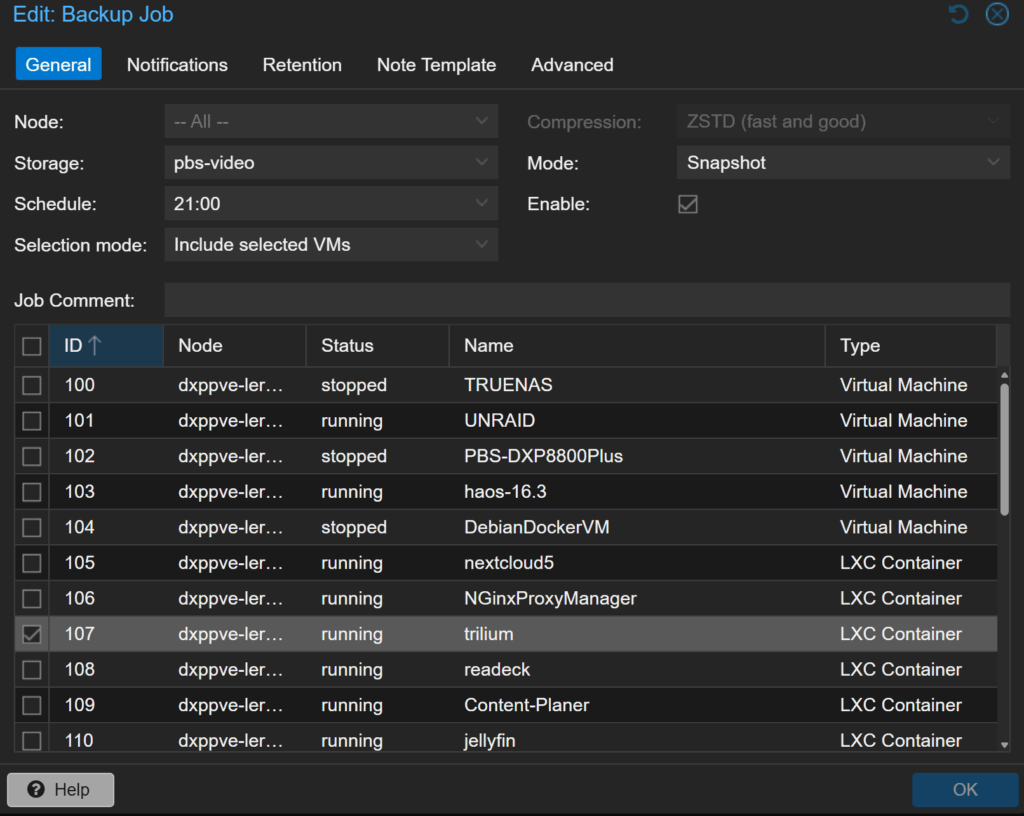
Backup-Job in Proxmox erstellen
Jetzt richte ich den eigentlichen Backup-Job ein:
Datacenter → Backup → Add
Schedule: täglich 21:00 Uhr
Mode: selected VMs (damit PBS sich nicht selbst sichert)
Optional:
Notifications per Mail
Compression Zstandard
Bandwidth-Limit
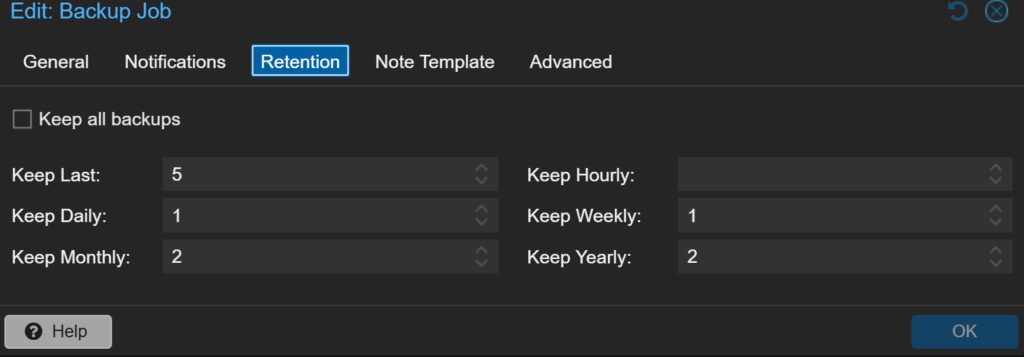
Retention – wie viele Backups ich behalte
Hier verwende ich eine Mischung aus kurz und langfristig:
Keep Last: 5
Keep Daily: 1
Keep Weekly: 1
Keep Monthly: 2
Keep Yearly: 2
Damit habe ich:
schnelle Wiederherstellung
Schutz vor Ransomware
sauberen Versionsverlauf
Backup testen
Ich starte den Job manuell:
Backup → Run now
Wenn die VM danach im Datastore auftaucht, weiß ich: Das Grundsetup passt.
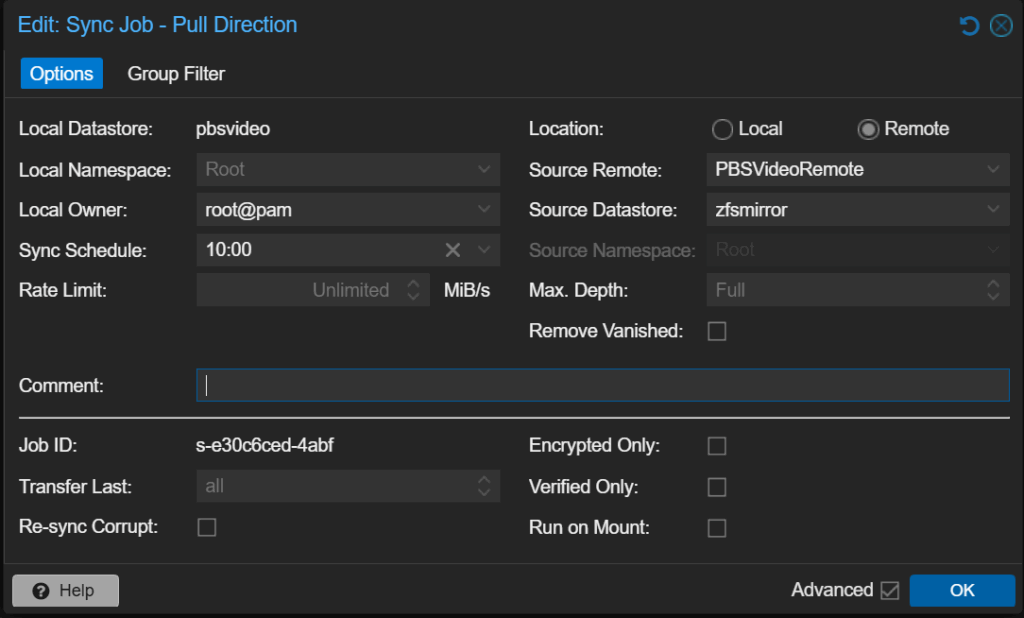
Mein zweiter PBS – Remote Sync für echte Sicherheit
Jetzt kommt der wichtigste Teil: Backups müssen extern gespeichert werden.
Seit 2019 setze ich Roborock-Saugroboter zuverlässig in meinem Zuhause ein. Von älteren Modellen bis hin zu aktuellen Geräten arbeiten sie täglich für uns – und sind für unsere Familie nicht mehr wegzudenken. Gerade weil wir in jedem Stockwerk einen Roborock nutzen, ist mir eine effiziente Integration in Home Assistant besonders wichtig.
Bereits vor längerer Zeit hatte ich dazu ein Video sowie ein Skript bereitgestellt. Dieses funktionierte zuverlässig, war jedoch an ein grundlegendes Problem gebunden: Es arbeitete auf Geräte-IDs statt Entitäten. Wenn ein neuer Roboter hinzukam, musste das gesamte Skript manuell angepasst werden. Da bei uns immer wieder ein neues Modell seinen Platz findet, wurde diese Anpassung zunehmend unübersichtlich. Aus diesem Grund habe ich eine modernisierte, flexiblere Lösung entwickelt.
In diesem Beitrag zeige ich Schritt für Schritt, wie du:
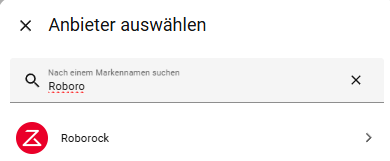
Roborock korrekt in Home Assistant einbindest
die Roborock Custom Map Integration installierst
die Vacuum Map Card einrichtest
Räume sauber konfigurierst
die Karte vollständig nutzen kannst
Das Ziel ist, Roborock komfortabel und visuell ansprechend zu steuern – ganz ohne komplexe Skriptanpassungen.
Unterstützung des Kanals
Die Erstellung meiner Skripte und Videos ist mit einem erheblichen zeitlichen Aufwand verbunden – von der technischen Vorbereitung und intensiven Recherche bis hin zu Tests, Aufnahmen und Nachbearbeitung. Alle Inhalte stelle ich dir dennoch vollständig kostenlos zur Verfügung.
Aktuell gibt es in den Black Weeks besonders attraktive Angebote. Ich selbst habe mir zu diesen hervorragenden Konditionen einen neuen Roborock-Saugroboter gegönnt – die Preise sind wirklich stark.
Wenn du ebenfalls über den Kauf eines Roborock nachdenkst, kannst du meinen Kanal und meine Arbeit wirkungsvoll unterstützen, indem du den Roboter über meinen Affiliate-Link bestellst. Für dich bleibt der Preis unverändert, aber ein kleiner Anteil des Kaufpreises hilft mir, weiterhin hochwertige Inhalte bereitzustellen. Wenn du vielleicht etwas anderes in den Black Wecks kaufen möchtest, kannst du mich dennoch unterstützen, wenn du meinen allgemeinen amazon Link für deinen Einkauf verwendest.
[Dual Anti-Tangle-System] Entdecke das revolutionäre doppelte Verhedderungsschutz-System des roborock Qrevo Curv mit Hauptbürste und Seitenbürste, einfach perfekt für den Umgang mit langen Haaren und für haustierfreundliche Wohnungen. Genieße eine Reinigung ohne verhedderte Haare und ähnliches, die Bürste reinigt sich fast von selbst.
[Extreme Saugkraft von 18.500 Pa] Branchenführende 18.500 Pa HyperForce Saugkraft in Kombination mit den Borsten der DuoDivide Bürste garantieren, dass der roborock Qrevo Curv auch anspruchsvolle Stellen wie Teppiche und Lücken in harten Böden gründlich reinigt und dabei selbst die kleinsten Partikel entfernt.
[FlexiArm Technologie] Die FlexiArm Arc Seitenbürste und das Kantenwischsystem, die exklusiv von Roborock angeboten werden, ermöglichen eine unvergleichliche Reinigungsabdeckung, da blinde Flecken beseitigt werden und somit kein Schmutz zurückbleibt.
[AdaptiLift Chassis] Erreiche ein höheres Niveau bei der Reinigung mit dem AdaptiLift Chassis, einer Premiere in der Branche, bei der viele verschiedene Anhebezustände dank drei unabhängig einstellbarer Räder erreicht werden können. So kann das gesamte Chassis um 10 mm angehoben werden oder nur die vordere, hintere, linke oder rechte Hälfte, damit die Anpassung an deine heimische Umgebung problemlos möglich ist.
[75 °C Heißwasser-Moppwäsche] Beseitige problemlos hartnäckige Flecken und fettige Verschmutzungen mit 75 °C heißem Wasser von deinen Mopps, gleichermaßen perfekt für Küchen und Essbereiche. Das heiße Wasser beseitigt über 99,99 % der Bakterien und gewährleistet optimale Hygiene. Mit drei einstellbaren Temperatureinstellungen bist du auf jedes Reinigungsszenario vorbereitet.
7,98cm Ultraflaches Design – Dank des autonomen StarSight Systems 2.0 der nächsten Generation ist der Saros 10R unglaublich smart und beeindruckend flach. Mit seiner hochentwickelten Positionierungs- und Kartierungsfunktiornen navigiert er mühelos unter Sofas und Betten.
Autonomes StarSight System 2.0 – Mithilfe fortschrittlicher Technologie zur Vermeidung seitlicher Hindernisse gleitet er mühelos um unregelmäßig geformte Möbel und Wände herum und reinigt sogar die Umgebung herumliegender Kabel garantiert gründlich.
Zero-Tangle-System – Ständige Wartung der Bürste ist für dich kein Thema mehr- dank des revolutionären Anti-Tangle-Systems an Hauptbürste und Seitenbürste. Das System reinigt sich selbst und kommt selbst mit langen Haaren zurecht. Dank HyperForce Saugleistung verschwinden Staub und Schmutz auf verschiedenen Arten von Böden und Teppichen, da auch die kleinsten Partikel spurlos beseitigt werden.
FlexiArm Riser Seitenbürste und Mopp – Die FlexiArm Technologie ist die Grundlage der doppelten Roboterarme für die Seitenbürste und den Mopp, damit Schmutz aus Ecken, an Kanten und unter Möbeln gekonnt aufgekehrt wird.
AdaptiLift Chassis als Branchenpremiere – Das gesamte Gehäuse kann abgenommen werden. Dabei sind die drei Räder unabhängig voneinander einstellbar. So erreicht dein Roborock auch schwer erreichbarre Stellen wie ein allrad-betriebener Geländewagen – für optimale Reinigungsabdeckung.
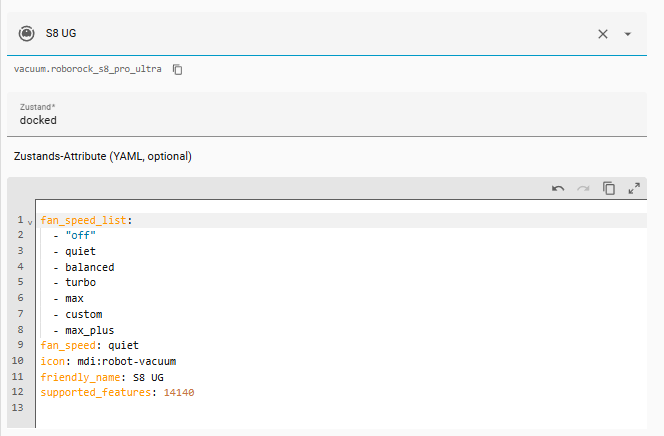
Roborock Core Integration installieren
Ich beginne in Home Assistant mit einer sauberen Testumgebung, sodass jeder Schritt nachvollziehbar ist. Die Core Integration lässt sich über Einstellungen → Geräte & Dienste → Integration hinzufügen installieren. Nach Eingabe der E-Mail-Adresse und des Bestätigungscodes erscheinen alle Roborock-Geräte automatisch in der Übersicht.
Damit steht das Fundament, auf dem die gesamte spätere Kartenfunktionalität aufbaut.
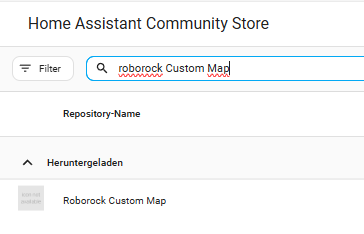
Custom Map Integration über HACS installieren
Die Vacuum Map Card benötigt spezielle Map-Datenstrukturen. Die normale Roborock-Integration stellt diese jedoch nicht vollständig bereit. Genau dafür dient die Roborock Custom Map Integration.
Nach dem Öffnen des Repositorys in HACS sucht man nach Roborock Custom Map Integration und drückt auf herunterladen. Anschließend ist ein Neustart von Home Assistant erforderlich. Roborock
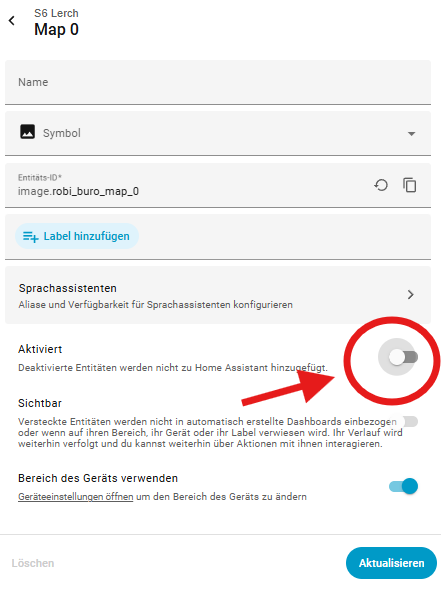
Wichtig: Die bisherige Image-Entität des Roboters sollte deaktiviert werden. Die neue Custom-Image-Entität wird später in der Vacuum Map Card genutzt.
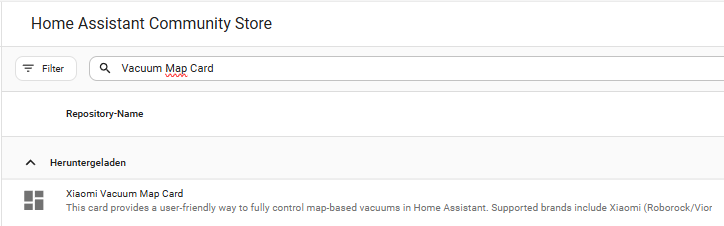
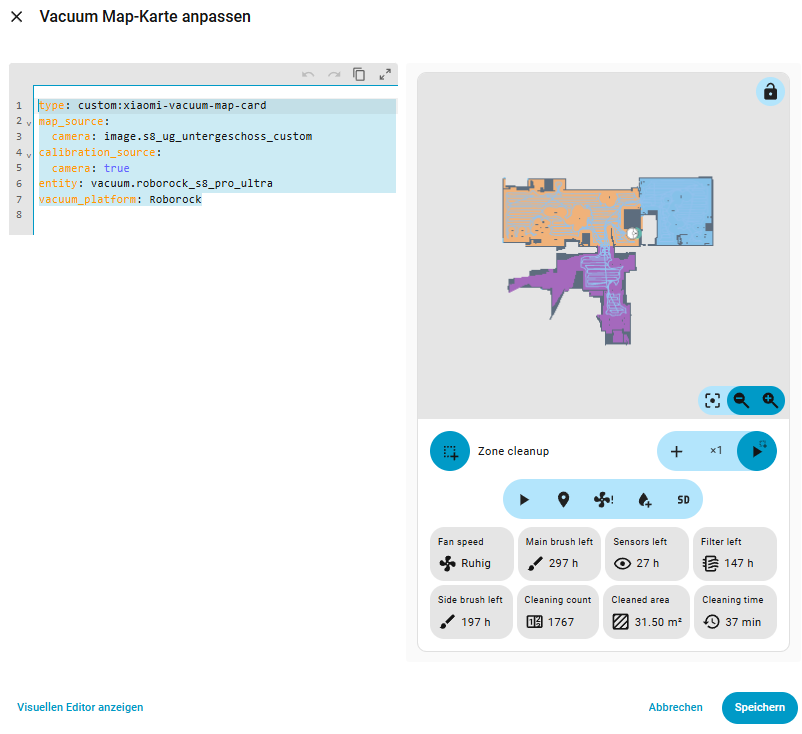
Vacuum Map Card installieren
Die Karte selbst wird ebenfalls über HACS installiert.
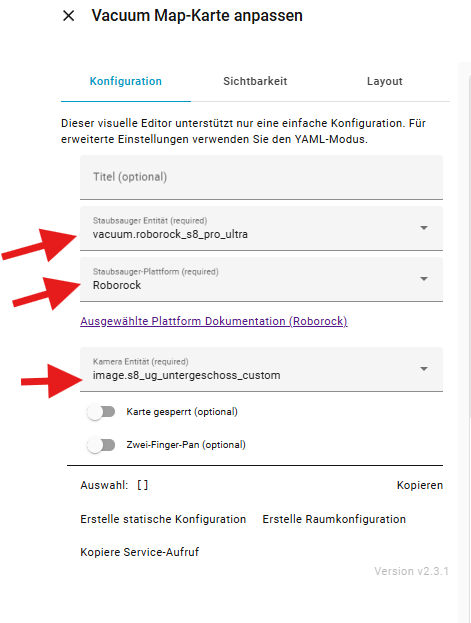
Ein Neustart ist hier nicht notwendig. Danach kann ich direkt im Dashboard eine neue Karte hinzufügen und folgende Einstellungen setzen:
Plattform: Roborock
Staubsauger: Eure Sauger Entität
Image: die neue, durch die Custom Map Integration erzeugte Map-Entität
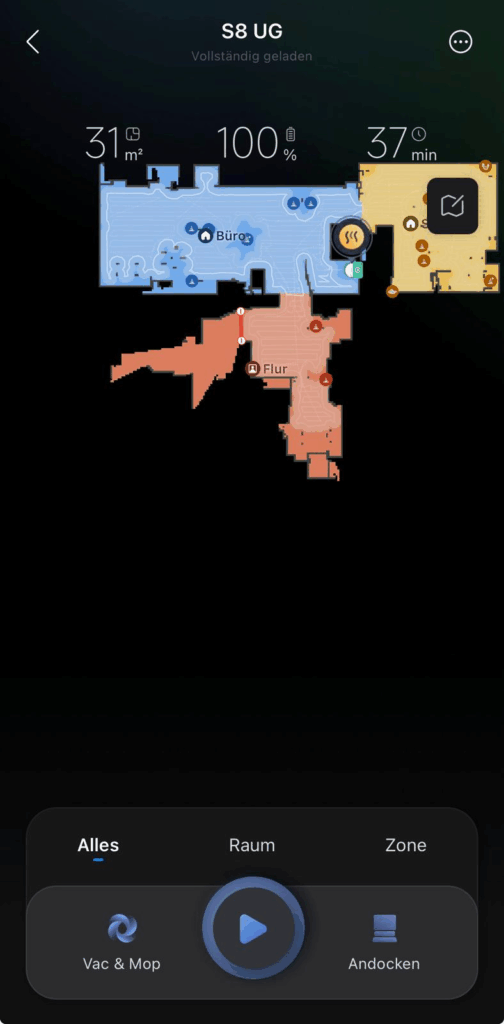
Die Karte zeigt nun die vollständige Umgebung an und bildet die Grundlage für die spätere Raumsteuerung.
Räume korrekt einrichten
Damit die Karte weiß, welche Bereiche ausgewählt werden können, müssen die Räume in der Roborock App korrekt definiert bzw. bereinigt werden.
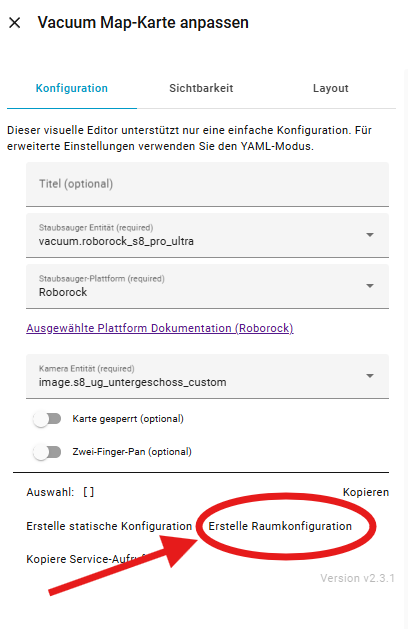
Über Karte bearbeiten → Erstelle Raumkonfiguration wird die Raumkonfiguration ausgelesen und im YAML Code der Karte angelegt. Im Code-Editor kann man dann die Erstellung überprüfen.
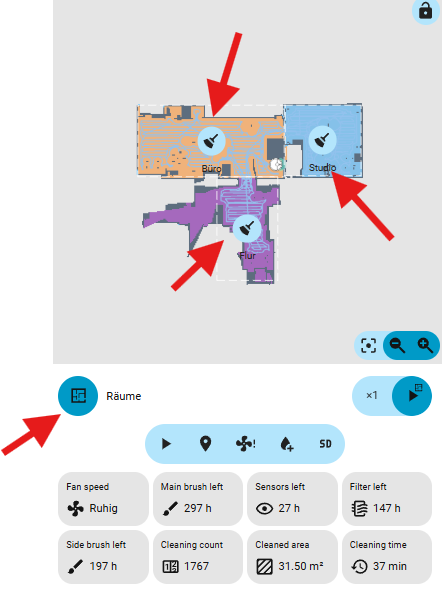
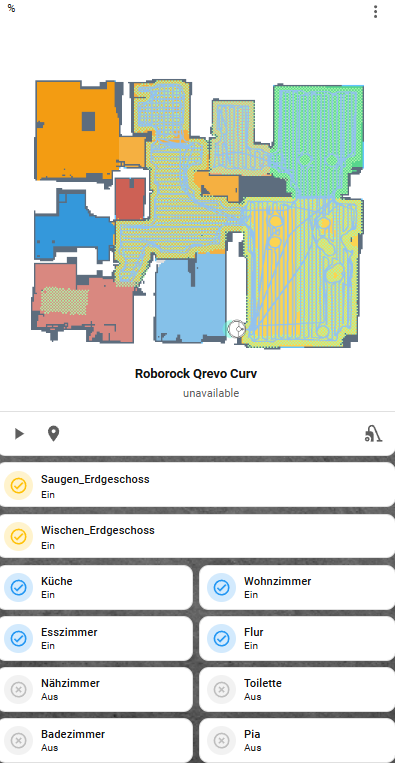
Hier zeigt Home Assistant zwar sämtliche Räume an, allerdings meist in mehrfacher Ausführung. Ich lösche alle überflüssigen Einträge und behalte nur diejenigen, die tatsächlich existieren – in meinem Fall Flur, Studio und Büro. Mir ist dabei aufgefallen, wenn man von unten nach oben geht, dann hat man an den letzten Stellen immer die korrekten Räume mit ihren IDs. D.h. ich geht wie im Beispiel Studio, Büro, Flur nach oben und löscht wie im Video gezeigt die überflüssigen Räume
Nach dem Speichern erscheinen die Räume korrekt und lassen sich über die Karte selektieren.
Erweiterte Reinigungsoptionen – ohne Skriptanpassungen
Viele Anwender starten die Reinigung direkt über die Karte und stellen die gewünschten Parameter dort ein. Das funktioniert zuverlässig. Auch Saugleistung, Modi und Wischintensitäten lassen sich dort einstellen.
Da ich selbst häufig erst sauge und anschließend wische, habe ich ein eigenes erweitertes Vorgehen entwickelt. Dieses ermöglicht es mir über ein Skript erst zu saugen und dann zu wischen und gleichzeitig alle relevanten Parameter vorzubelegen.
Die benötigten Entitäten – etwa für Mop-Modus, Wischintensität oder Ventilatorgeschwindigkeit – lassen sich zuvor über die Entwicklerwerkzeuge bestimmen. Wichtig, achtet darauf, dass wir die korrekten Attribute bei der Übergabe an das Skript übernehmt.
Dynamisches Skript für erst Saugen und dann Wischen ( nur für Roborock Saugroboter)
Damit die Reinigung komfortabel über einen einzigen Button in der Karte ausgelöst werden kann, erweitere ich die Kartenkonfiguration. Dadurch entsteht ein zusätzlicher Menüpunkt wie „Saugen und Wischen“. Dieser greift auf die zuvor definierten Parameter zu und löst die Reinigungssequenz aus. Roborock
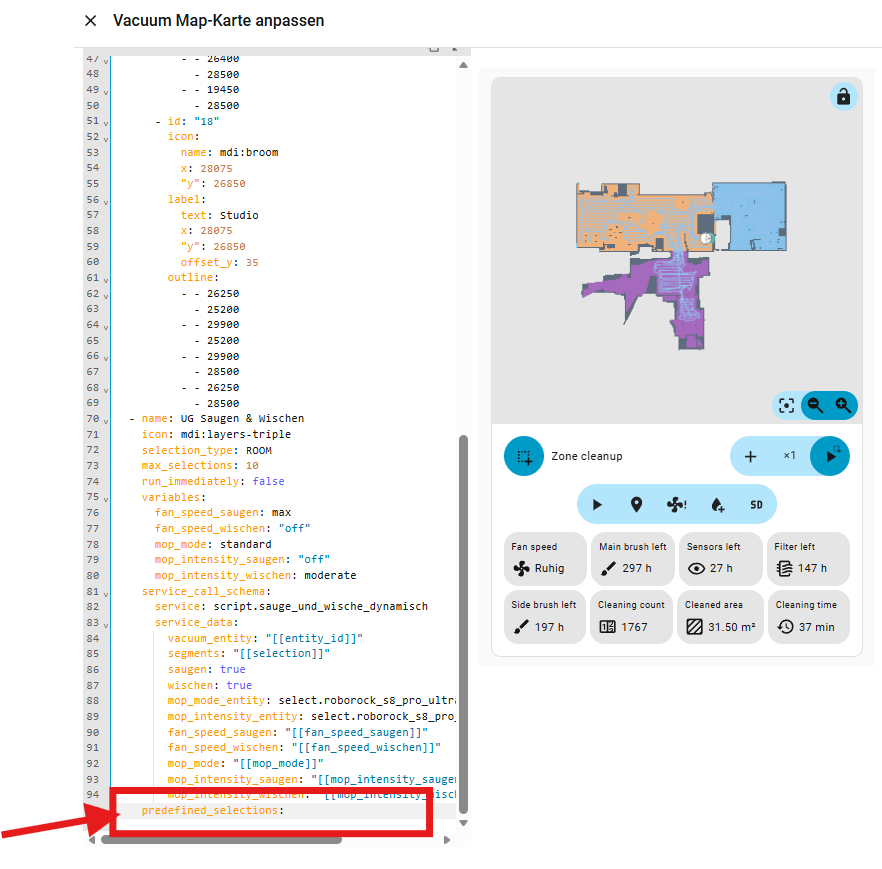
Um jetzt ein zusätzliches Skript aufzurufen, müssen wir ein paar Parameter im YAML Code ergänzen. Diese fügen wird direkt unterhalb der vorherigen Eintragungen ( bei euch demnach nach euren Räumen mit den Koordinaten ) ein.
Die Parameter fan_speed_saugen, fan_speed_wischen, mop_intensity_saugen. mop_intensity_wischen, sind nach den zuvor ausgelesenen Attributen aus den Entwicklerwerkzeugen einzusetzen. Bitte nicht einfach kopieren, denn jeder Roborock Roboter hat hier unter Umständen andere Namen in den Attributen!
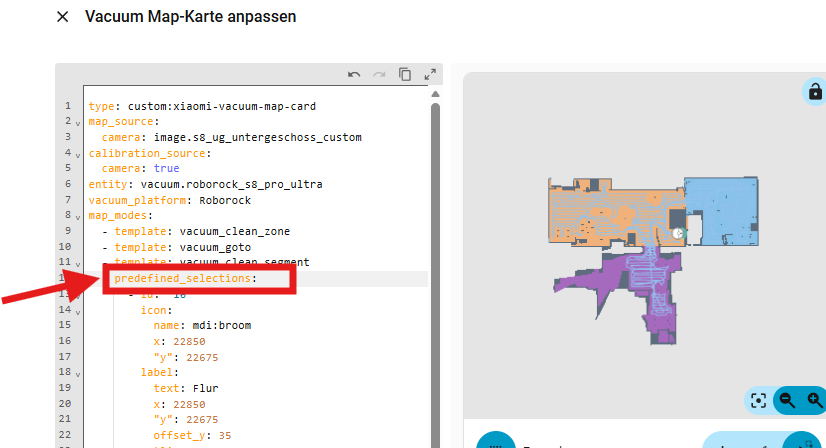
Jetzt fehlen und bei de predefined_selections: nur noch die Räume. Hier gibt es jetzt zwei Möglichkeiten. Entweder man kopiert sich die „predefined_selections“ aus dem vorherigen Code Abschnitt, oder aber man nutzt einen YAML-Anker. Ich nutze einen YAML-Anker, um Raumdefinitionen nicht doppelt pflegen zu müssen. Das reduziert die Fehleranfälligkeit und erleichtert spätere Anpassungen.
Dazu geht an die erste Stelle mit“ predefined_selections“ im Code.
und fügt dort folgendes nach dem Doppelpunkt ein:
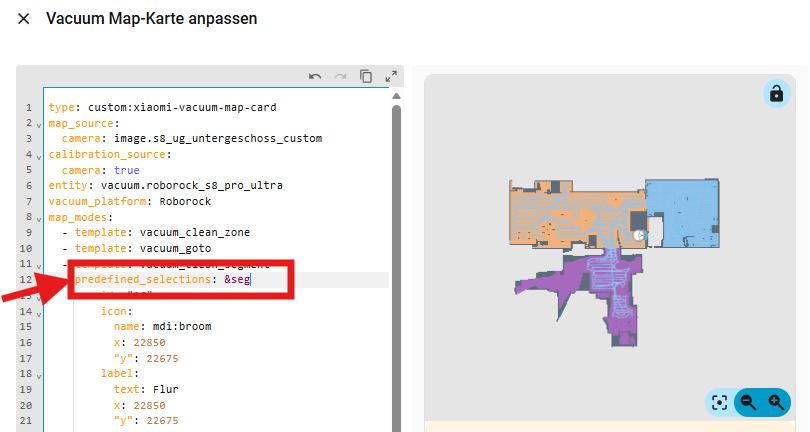
&seg
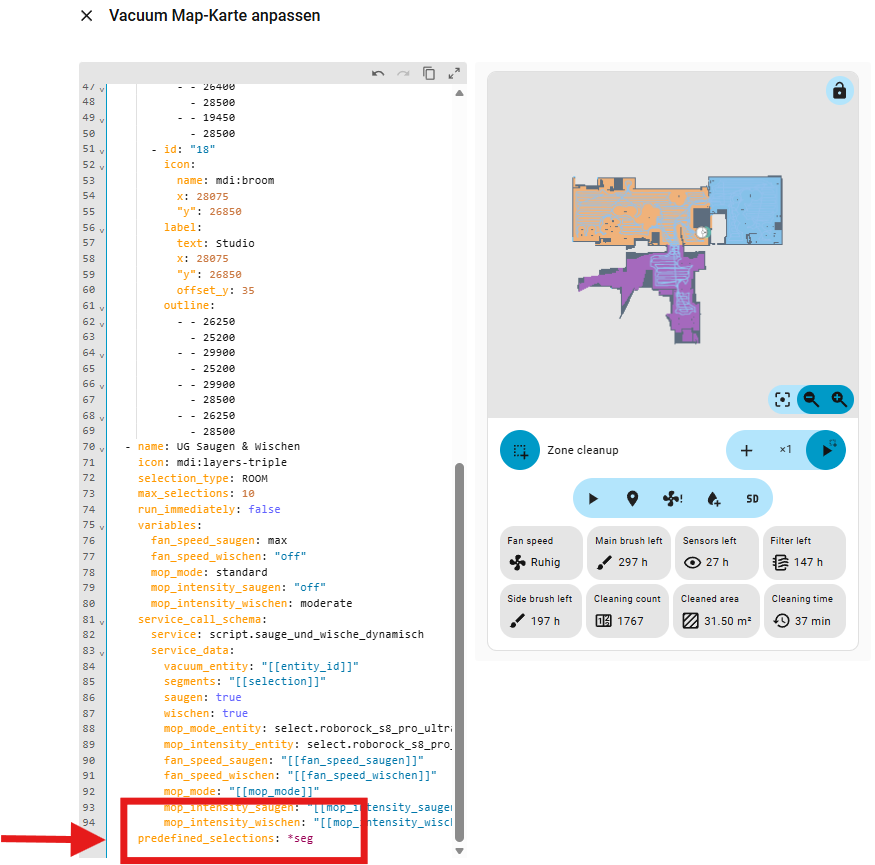
Dann geht zum letzten Eintrag mit „predefined_selections“, also der Blog, den ihr zuvor eingefügt hattet.
Dort fügt nun nach dem Doppelpunkt ein :
*seg
ein.
Jetzt nur noch auf „Speichern“ drücken. Und der Abschnitt nach eurem letzten „predefined_selections“ wird automatisch mit den Eintragungen aus dem oberen Abschnitt gefüllt. Das Verfahren verringert aus meiner Sicht die Fehleranfälligkeit beim Kopieren und Einfügen.
Um euch die Möglichkeit zu geben eure YAML Konfiguration der Vacuum Map Card abzugleichen, habt ihr hier nochmal den kompletten YAML Code meiner eigenen Konfiguration. Bitte beachtet, dass ihr eure eigene Raumkonfiguration erstellen müsst, da diese in meinem Setup auf unsere Raumkonfiguration in der Roborock App abgestimmt ist!
Nach der vollständigen Einrichtung lassen sich Räume über die Vacuum Map Card einfach auswählen. Wenn ich einzelne Bereiche oder mehrere Räume zu einer kombinierten Reinigung zusammenfasse, genügt ein Klick auf den jeweiligen Button. Der Roboter fährt die Bereiche nacheinander ab und führt, je nach Einstellung, Saugen und Wischen exakt in dieser Reihenfolge aus. Roborock
Diese Lösung funktioniert zuverlässig mit allen Roborock-Modellen, die von der Core-Integration unterstützt werden.
Fazit
Durch die Kombination aus Roborock Core Integration, Roborock Custom Map Integration und Vacuum Map Card wird Home Assistant deutlich leistungsfähiger. Die Kartenansicht erleichtert die Steuerung im Alltag erheblich und bietet eine sehr klare Übersicht über alle Räume.
Während bei uns zu Hause meine Frau die puristische Ansicht bevorzugt, nutze ich gerne die Vacuum Map Card mit den erweiterten Funktionen. Beide Varianten haben ihre Vorteile – entscheidend ist, was im Alltag besser funktioniert. Den Blogbeitrag zu meiner alten Lösung findet ihr hier:
Wenn du eigene Ideen oder Optimierungen hast, freue ich mich über Rückmeldungen. Ergänzende Dateien und Konfigurationen findest du wie gewohnt auf meiner Blogseite.
Unraid unter Proxmox installieren – Mein komplettes HomeLab-Setup
In diesem Beitrag möchte ich dir zeigen, wie ich Unraid unter Proxmox in meinem HomeLab betreibe – und warum dieses Setup für mich aktuell die beste Kombination aus Energieeffizienz, Flexibilität und Performance bietet. Ich nutze Proxmox schon lange als zentrale Virtualisierungsebene. Die Möglichkeit, darauf wiederum Unraid zu virtualisieren, ist für mich ein idealer Weg, moderne NAS-Funktionen mit der Flexibilität eines Linux-Hypervisors zu verbinden.
Gerade im privaten Umfeld spielt Stromverbrauch eine immer wichtigere Rolle. Während ZFS mit TrueNAS im professionellen Einsatz für mich der absolute Favorit ist, lege ich zuhause Wert darauf, dass Platten zuverlässig schlafen können und nicht permanent durchlaufen müssen. Und genau dort punktet Unraid enorm.
Warum ich Unraid unter Proxmox nutze
Zu Beginn war ich selbst skeptisch, ob eine Virtualisierung von Unraid überhaupt sinnvoll ist. In der Praxis hat sich das aber schnell als echte Lösung herausgestellt. Ich habe einerseits die komplette Kontrolle von Proxmox inklusive Snapshots, VMs, Netzwerkmanagement und ZFS-Speicher für meine virtuellen Maschinen. Gleichzeitig nutze ich die Stärken von Unraid, nämlich ein extrem flexibles Array, Caching, schlafende HDDs, Docker-Management und eine sehr unkomplizierte Erweiterbarkeit.
Was viele nicht wissen: Auf dem USB-Stick wird fast nie geschrieben. Der Stick dient in erster Linie als Boot-Medium, und lediglich Änderungen an der Konfiguration werden gespeichert. Dadurch ist er erstaunlich langlebig. Ich verwende Sticks mit garantiert eindeutiger GUID, da Unraid die Lizenz an diese ID bindet.
Mein Hardware-Setup*
In meinem Video habe ich ein UGREEN 4-Bay NAS als Beispiel genutzt. Mein produktives System ist das 8-Bay Modell mit deutlich mehr Kapazität. Die Vorgehensweise ist identisch, weshalb sich das Tutorial flexibel auf verschiedenste Hardware übertragen lässt.
In meinem Testsystem stecken vier 4-TB-HDDs, zwei NVMe-SSDs im ZFS-Mirror (für Proxmox selbst) und eine virtuelle 250-GB-Disk, die ich später als Cache-Laufwerk für Unraid verwende. Zusätzlich habe ich den Arbeitsspeicher auf 48 GB erweitert, was im Alltag angenehm ist, aber für Unraid selbst gar nicht nötig wäre.
Lieferumfang: 1 x Samsung 990 PRO NVMe M.2 SSD, Speicherkapazität: 2 TB
Vorbereitung des USB-Sticks*
Um Unraid nutzen zu können, lade ich das offizielle Flash-Tool herunter und spiele die aktuelle Version auf einen frisch formatierten Stick. Das geht wirklich unkompliziert. Wichtig ist nur, dass die GUID korrekt erkannt wird und der Stick zuverlässig von der Hardware gebootet werden kann. Danach stecke ich ihn in das UGREEN-NAS und kann in Proxmox direkt loslegen.
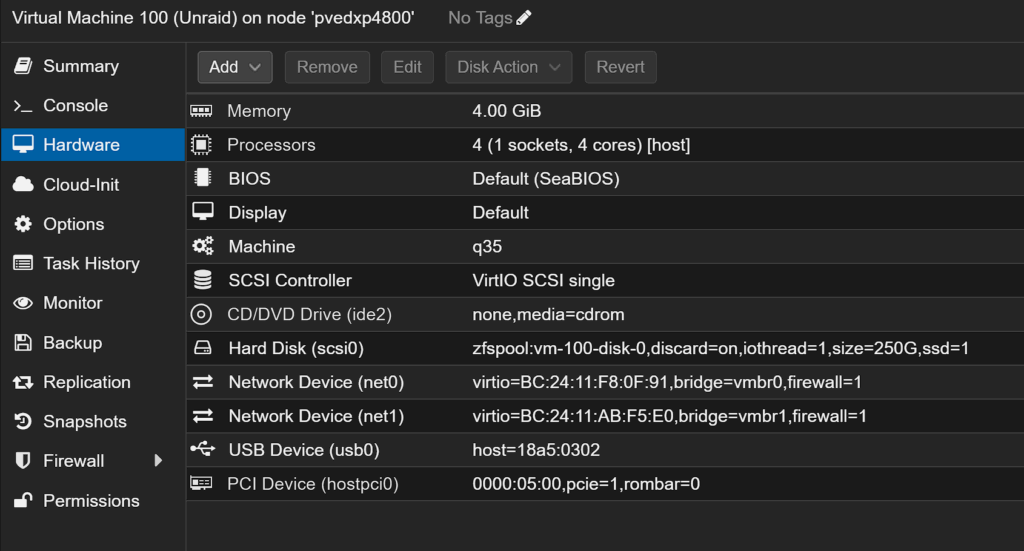
Die VM für Unraid ist schnell erstellt. Ich vergebe ihr einen Namen, lasse das Installationsmedium leer und wähle als Maschinentyp q35, damit alle modernen PCIe-Funktionen verfügbar sind. Anschließend stelle ich 4 GB Arbeitsspeicher und zwei bis vier CPU-Kerne bereit. Eine virtuelle Festplatte lege ich an dieser Stelle noch nicht an, da Unraid später die tatsächlichen HDDs direkt erhält.
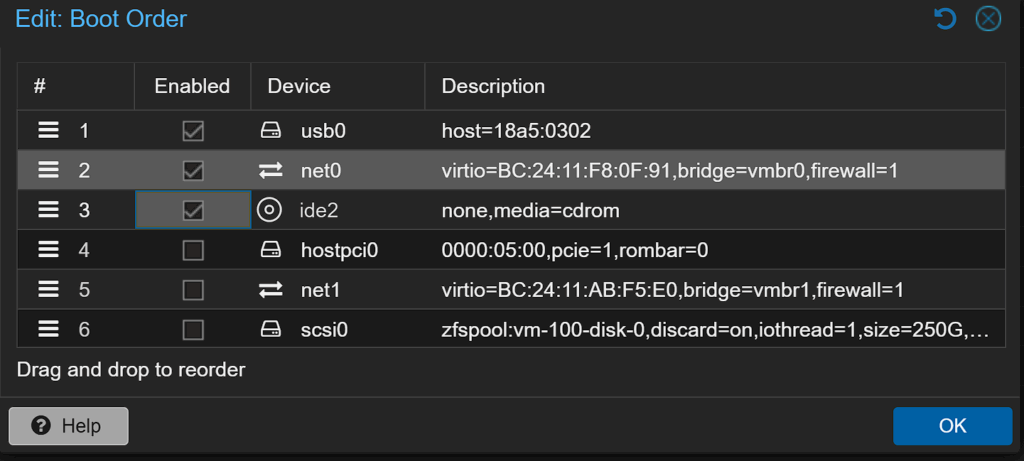
Damit die VM korrekt startet, passe ich anschließend die Bootreihenfolge an. Zuerst soll der USB-Stick booten. Die restlichen Order sind eigentlich überflüssig.
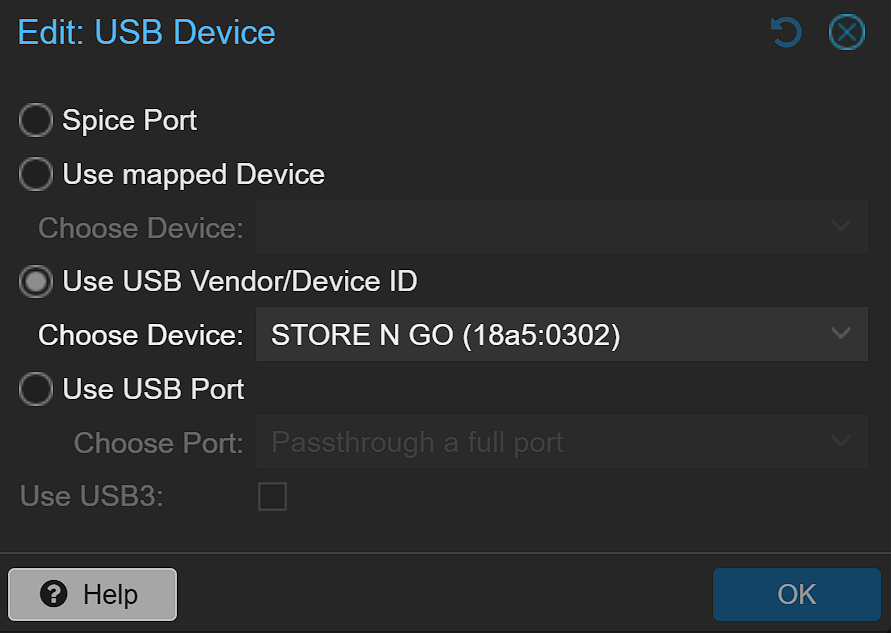
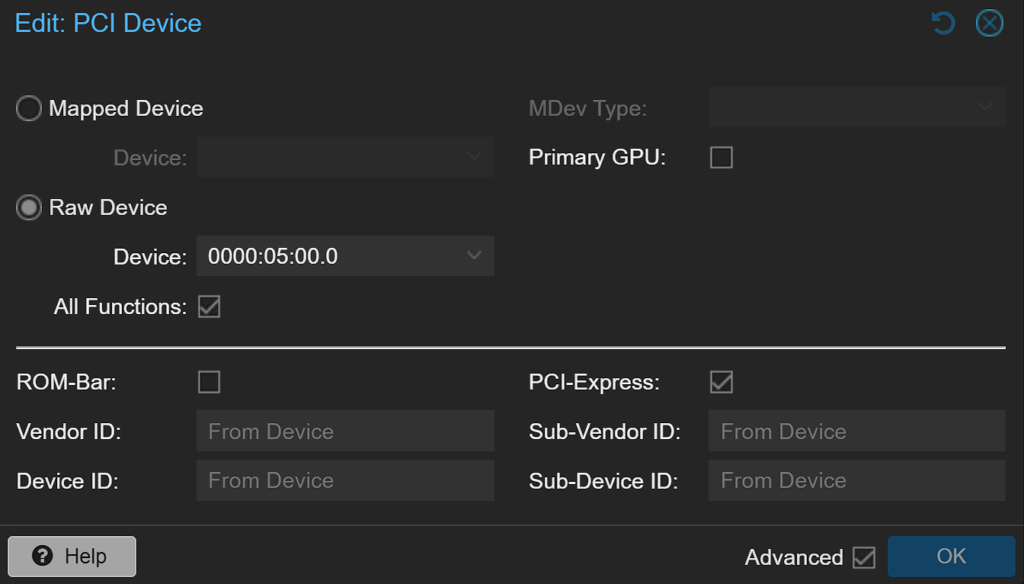
Passthrough von USB-Stick und SATA-Controller
Das ist der wichtigste Schritt des gesamten Setups. Der USB-Stick wird anhand seiner Vendor- und Device-ID durchgereicht. Das sorgt dafür, dass Unraid beim Start genau diesen Stick erkennt – unabhängig davon, an welchem Port er steckt.
Noch wichtiger ist das Durchreichen des SATA-Controllers. Ich wähle also unter den PCI-Geräten den kompletten Controller aus, aktiviere „Alle Funktionen“ und reiche ihn mit PCIe-Unterstützung an die VM durch. Das bedeutet: Unraid sieht die HDDs so, als wären sie direkt über SATA angeschlossen. Keine virtuelle Zwischenschicht, keine Geschwindigkeitseinbußen – echtes Bare-Metal-Feeling.
Die zusätzliche virtuelle SCSI-Disk lege ich als SSD-emuliertes Laufwerk an. Sie dient später als Cache-Drive und trägt massiv dazu bei, dass die physikalischen HDDs lange schlafen können.
Der erste Start von Unraid
Nach dem Start bootet Unraid direkt vom USB-Stick. Sobald eine IP vergeben wurde, öffne ich die Weboberfläche und vergebe zuerst ein Administrator-Passwort. Danach starte ich die kostenlose Trial oder nutze meinen vorhandenen Lizenzschlüssel.
Es ist wichtig zu wissen, dass die Lizenz fest an die eindeutige Stick-ID gebunden ist. Wechselst du den Stick, musst du die Lizenz übertragen – daher lohnt sich ein qualitativ hochwertiges Modell.
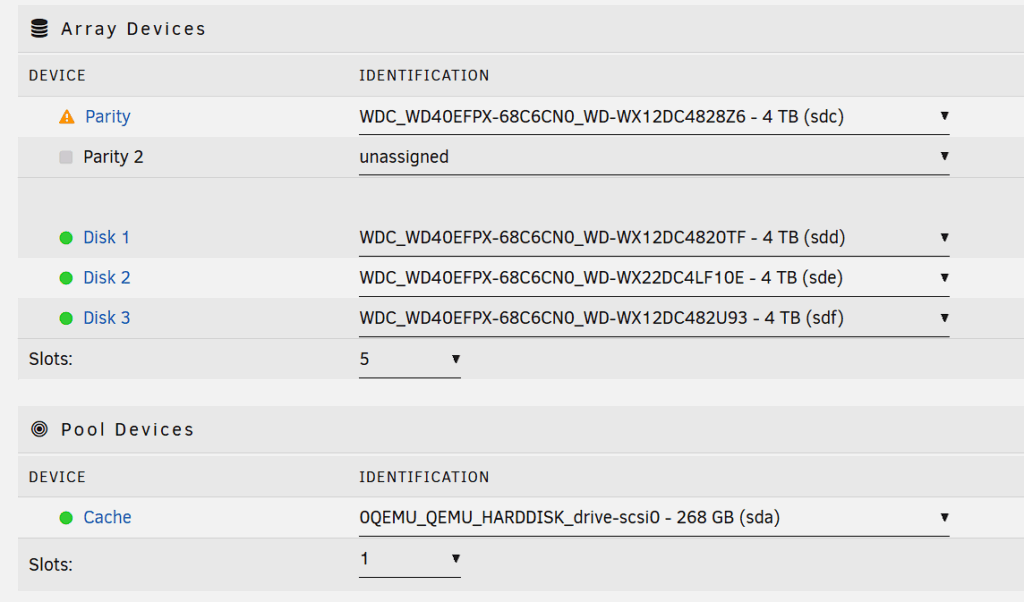
Einrichtung des Arrays
Jetzt geht es ans Herzstück von Unraid: Das Array. Ich entscheide mich bewusst für ein klassisches Setup mit Paritätsfestplatte. Für mich ist das der beste Kompromiss zwischen Sicherheit, Flexibilität und Energieverbrauch. Bei einem ZFS-System müssen alle Platten permanent laufen, da die Datenstruktur über mehrere Platten gleichzeitig verteilt ist. Unraid hingegen erlaubt es, Platten einzeln schlafen zu legen, solange sie nicht aktiv benötigt werden.
Ich ordne die Platten der Reihe nach zu, vergebe die Parity-Disk und ordne zwei oder drei weitere HDDs als Datenlaufwerke zu. Das Cache-Drive definiere ich ebenfalls direkt, sodass größere Schreibvorgänge zunächst auf den schnellen virtuellen NVMe-Speicher gehen.
Der erste Parity-Build dauert mehrere Stunden, was normal ist. Während dieser Zeit sollten möglichst keine Daten auf das Array geschrieben werden.
Energie sparen mit Spindown und Cache
Einer der Hauptgründe, warum ich Unraid privat so gerne nutze, ist der deutlich geringere Stromverbrauch. Sobald die Parität erstellt wurde, stelle ich das automatische Einschlafen der HDDs ein. Bei mir sind 15 Minuten ideal, aber 30 Minuten sind ebenfalls ein guter Wert, wenn regelmäßig kleinere Zugriffe stattfinden.
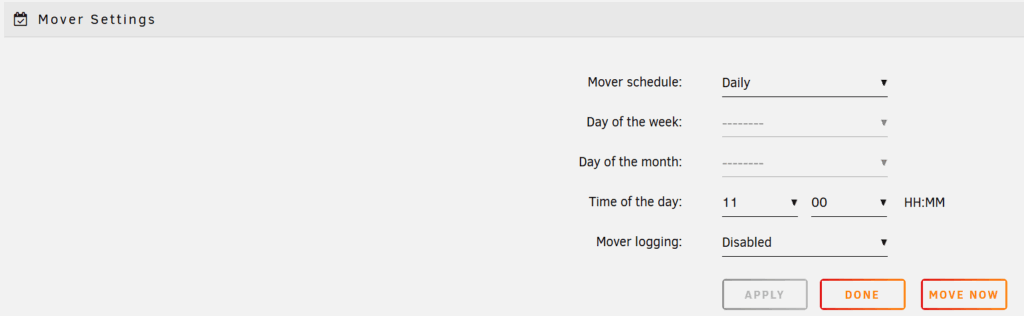
Damit die Platten wirklich zuverlässig schlafen können, ist das Cache-Drive entscheidend. Es nimmt alle kurzfristigen Schreibvorgänge auf, und erst später bewegt der sogenannte „Mover“ die Daten auf die HDDs. Ich lasse den Mover bewusst zu Zeiten laufen, in denen meine PV-Anlage Strom liefert – idealerweise mittags.
In Tests liegt mein System im Idle bei rund 30 W. Während der Parität waren es etwa 57 W. Mit größeren HDDs (7 200 U/min) steigt der Unterschied noch stärker an, weshalb ein stromsparendes Setup auf Dauer bares Geld spart.
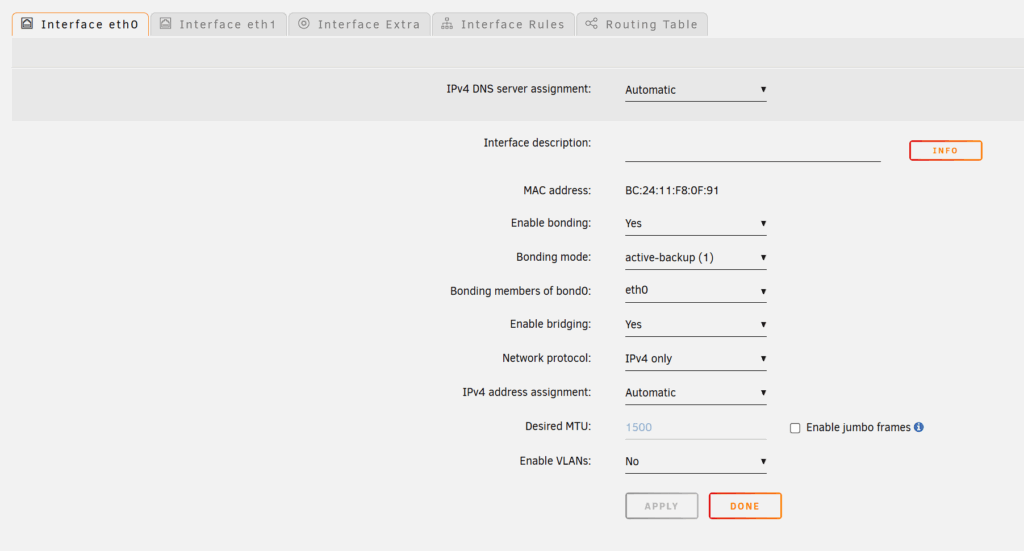
Netzwerk-Setup und 10-Gigabit-Anbindung
Unraid bekommt bei mir zunächst eine DHCP-Adresse, die ich im Router fest verankere. Für besonders schnelle Kopiervorgänge nutze ich zusätzlich die 10-Gigabit-Schnittstelle des UGREEN-NAS. Diese reiche ich ebenfalls an die VM durch und vergebe ihr eine eigene statische IP.
In meinen Tests erreiche ich über die 10-GbE-Verbindung bei Kopien auf den Cache problemlos Übertragungsraten von über 200 MB/s. Gerade wenn ich Daten auf das NAS oder zwischen VMs verschiebe, bringt das spürbare Vorteile. Ich weiß, die 10GbE Schnittstelle sollte ja viel mehr können. Aber meine VM , von der ich aus kopiere liegt auf langsamen SSD Speicher, da geht nicht mehr. Mit einem physischen Rechner und einer schnellen NVME lassen sich aber die Bandbereiten fast vollständig ausnutzen. Mir geht es hier aber primär um Energie und nicht um Performance.
Docker, Apps und Benutzer
Nachdem das System steht, aktiviere ich Docker und installiere das Community-Apps-Plugin. Damit stehen mir hunderte Anwendungen direkt mit einem Klick zur Verfügung – von Medienservern über Backuplösungen bis hin zu KI-Tools.
Anschließend lege ich Benutzer und Freigaben an. Der typische Workflow sieht bei mir so aus, dass ich ein Share erst auf den Cache schreiben lasse und der Mover die Dateien später automatisch ins Array verschiebt. Das sorgt dafür, dass die HDDs über weite Strecken komplett schlafen können.
Warum Unraid für mein HomeLab bleibt
Auch wenn ich im professionellen Umfeld TrueNAS weiterhin sehr gerne einsetze, ist Unraid für mein HomeLab inzwischen die erste Wahl. Es erlaubt mir, flexibel Platten zu kombinieren, ja, es sind sogar Festplatten mit unterschiedlichen Größen möglich, sie einzeln schlafen zu lassen, Docker bequem zu verwalten und die Hardware sehr frei zu konfigurieren. Energietechnisch habe ich damit ein System, das im Leerlauf nicht mehr verbraucht als ein kleiner Büro-PC – und gleichzeitig jederzeit erweiterbar bleibt.
Wenn du selbst ein HomeLab aufbaust und zwischen ZFS/TrueNAS und Unraid schwankst, kann ich dir nur empfehlen, einmal Unraid auszuprobieren. Gerade die Mischung aus Einfachheit, Flexibilität und Energieeffizienz macht das System im privaten Einsatz extrem attraktiv. Auch Unraid beherrscht mittlerweile ZFS. Aber der Fokus lag bei mir auf die Einsparung von Energie.
Kennst du das Problem, dass Home Assistant manchmal „denkt“, du bist nicht zu Hause – obwohl du gerade gemütlich auf der Couch sitzt? Oft liegt das daran, dass ein einzelner Sensor (z. B. dein Handy im WLAN) den Ausschlag gibt. Ist der Akku leer oder das WLAN kurz aus, geht Home Assistant davon aus: niemand zu Hause!
Genau hier kommt der Bayesian Sensor ins Spiel. Er arbeitet nicht mit starrer Logik, sondern mit Wahrscheinlichkeiten. Damit wird deine Präsenzerkennung so zuverlässig wie nie zuvor.
In diesem Beitrag zeige ich dir Schritt für Schritt, wie du den Bayesian Sensor in Home Assistant einrichtest, konfigurierst und sinnvoll in deine Automatisierungen einbindest.
Was ist der Bayesian Sensor?
Der Bayesian Sensor (oft auch „Bayes-Sensor“ genannt) ist eine Integration in Home Assistant, die auf dem Bayes’schen Wahrscheinlichkeitsprinzip basiert. Das klingt erst mal nach Statistik, ist aber unglaublich nützlich: Der Sensor kombiniert verschiedene Zustände (z. B. WLAN-Verbindung, Tür geöffnet, Bewegung erkannt) und berechnet daraus eine Gesamtwahrscheinlichkeit, ob du zu Hause bist oder nicht.
Das Entscheidende: Du kannst jedem Sensor eine eigene Gewichtung geben. So denkt dein Smart Home nicht mehr in „Ja/Nein“, sondern in „Wie wahrscheinlich ist es, dass jemand da ist?“
Beispiel:
WLAN ist verbunden → +20 %
Companion App meldet „Zuhause“ → +30 %
Haustür wurde geöffnet → +10 %
Bewegung im Flur → +15 %
➡️ Ab einer bestimmten Schwelle (z. B. 60 %) wird der Zustand auf „anwesend“ gesetzt.
Warum Wahrscheinlichkeiten besser sind als Logik
Die klassische Logik („UND“ / „ODER“) in Home Assistant ist anfällig für Störungen. Wenn du zum Beispiel folgende Bedingung nutzt:
„Nur wenn WLAN und Companion App beide ‘Home’ melden, gilt Anwesenheit als wahr“
…dann reicht ein kleiner WLAN-Aussetzer – und dein ganzes System glaubt, du bist weg. Lichter gehen aus, Heizung wird abgesenkt, und du wunderst dich, warum alles dunkel wird.
Mit dem Bayesian Sensor passiert das nicht. Er „denkt“ wie ein Mensch und gewichtet jede Information nach ihrer Verlässlichkeit.
Einrichtung des Bayesian Sensors in Home Assistant
🧭 Hinweis: Du findest die Integration unter Einstellungen → Geräte & Dienste → Integration hinzufügen → Bayesian Sensor
Ich zeige dir hier die wichtigsten Schritte an einem Beispiel für die Präsenzerkennung.
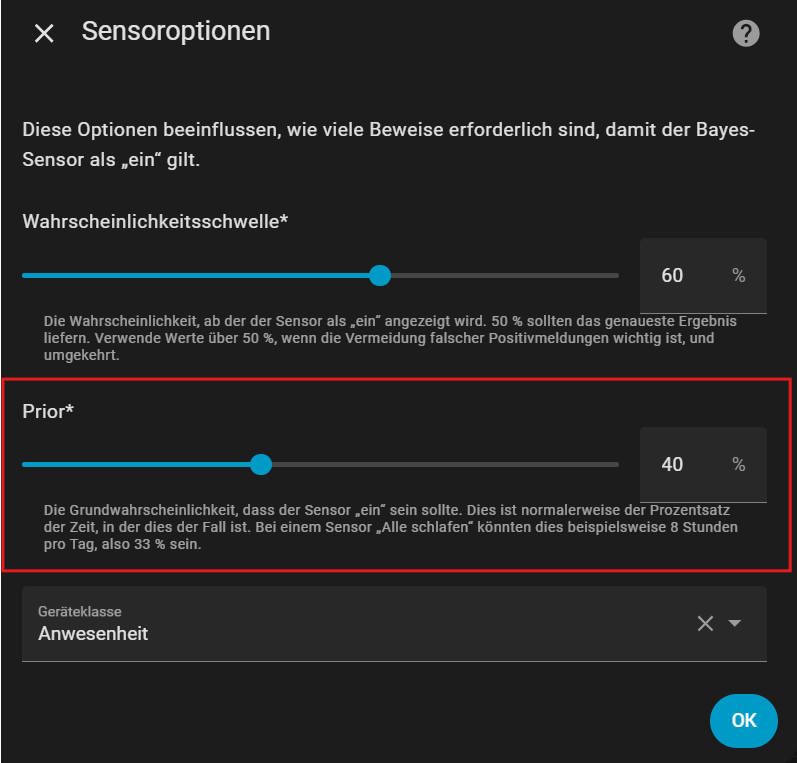
Grundwahrscheinlichkeit festlegen
Zuerst definierst du, wie wahrscheinlich es generell ist, dass du zu Hause bist. Wenn du z. B. werktags 8 Stunden arbeitest, kannst du sagen:
Grundwahrscheinlichkeit : 40 % , dass ich zu Hause bin
Die Wahrscheinlichkeitsschwelle habe ich auf 60% gelegt. D.h. wenn diese Schwelle überschritten wird, gilt der Zustand „zu Hause“ .
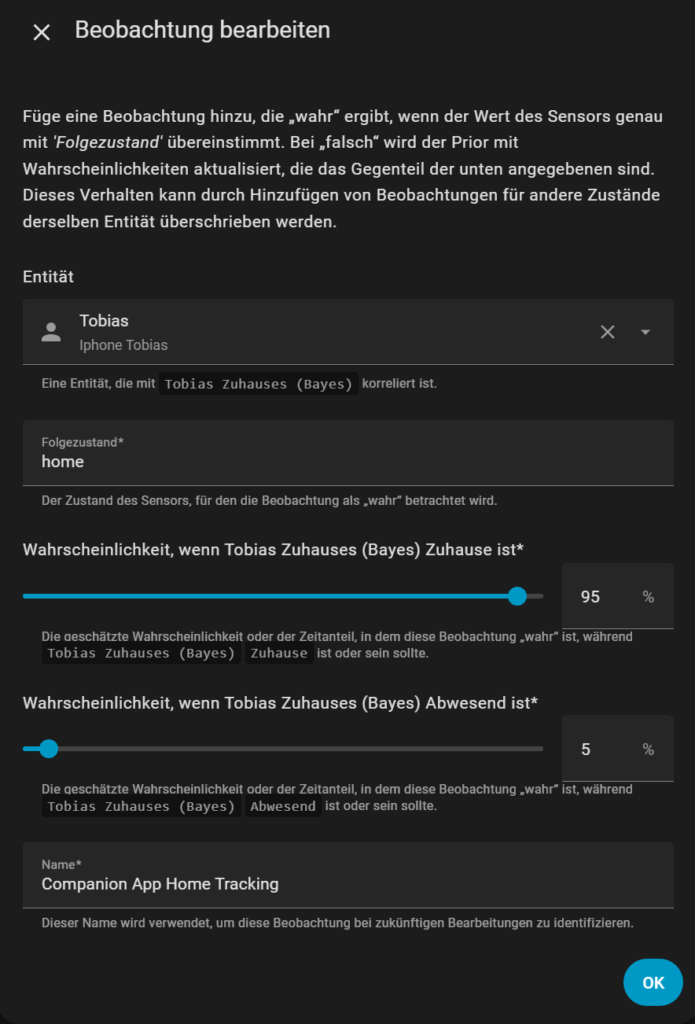
Beobachtungen (Observations) hinzufügen
Jetzt kommen deine Sensoren ins Spiel. Jede Beobachtung bekommt zwei Werte:
prob_given_true: Wahrscheinlichkeit, dass der Sensor „an“ ist, wenn du da bist
prob_given_false: Wahrscheinlichkeit, dass der Sensor „an“ ist, obwohl du nicht da bist
Hier ein Beispiel für die Companion App:
🧩 Damit sagst du: Wenn mein iPhone auf „home“ steht, bin ich mit 95 %iger Sicherheit zu Hause.
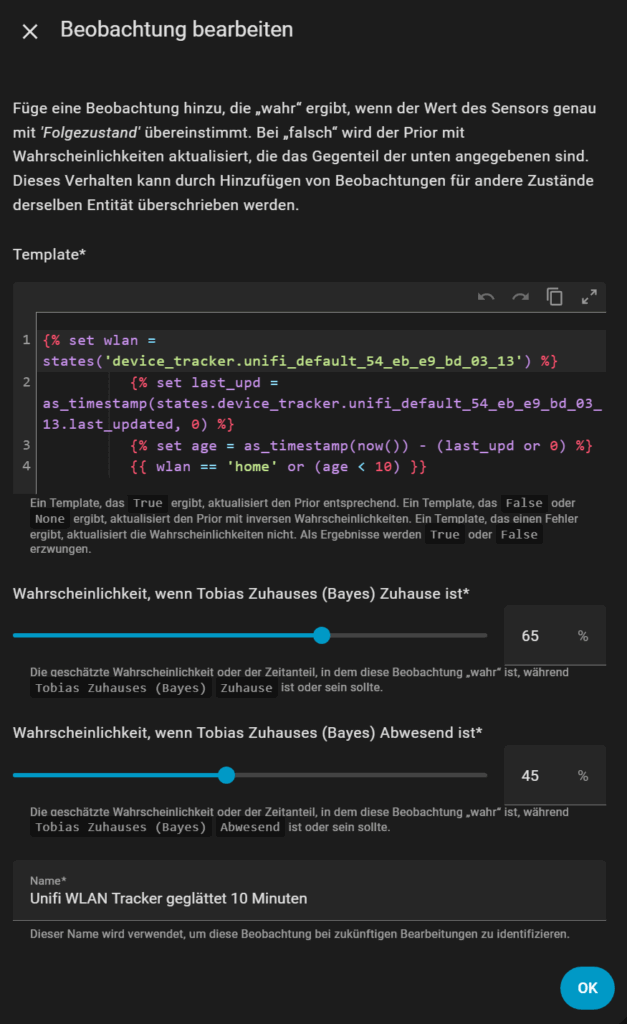
WLAN-Sensor hinzufügen
WLAN-Verbindungen sind nützlich, aber nicht immer zuverlässig (z. B. bei iPhones im Sleep-Modus). Ich nutze in meinem Setup Unifi, du kannst aber genauso gut die FritzBox-Integration oder einen Ping-Sensor verwenden.
Beispiel-Template (mit 10-Minuten-Check):
{% set wlan = states('device_tracker.unifi_default_54_eb_e9_bd_03_13') %}
{% set last_upd = as_timestamp(states.device_tracker.unifi_default_54_eb_e9_bd_03_13.last_updated, 0) %}
{% set age = as_timestamp(now()) - (last_upd or 0) %}
{{ wlan == 'home' or (age < 10) }}
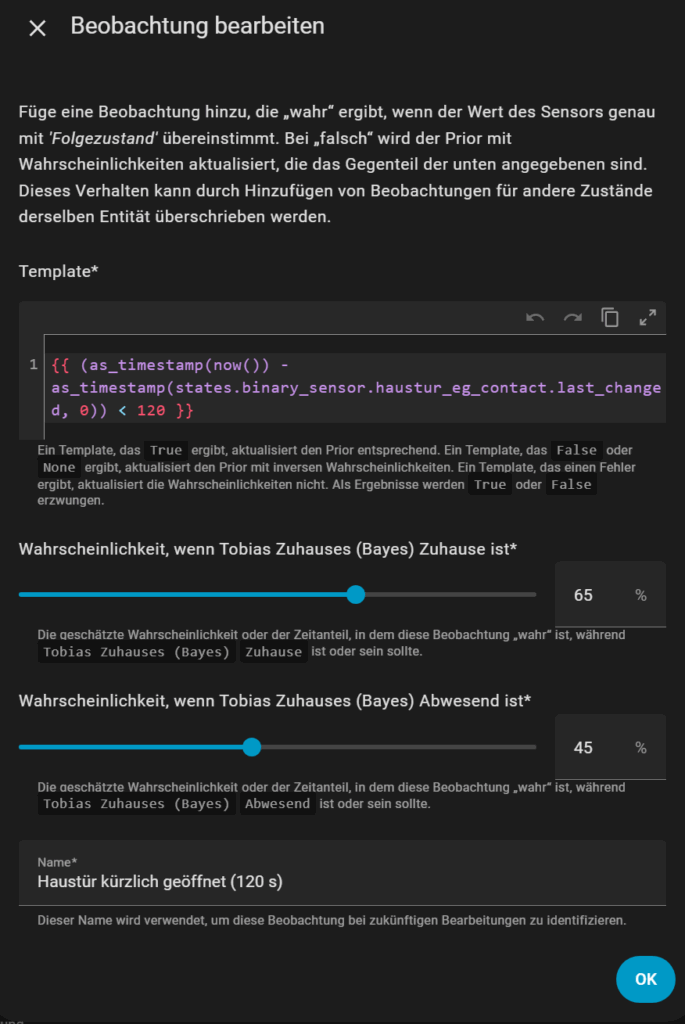
Türkontakt als zusätzlicher Indikator
Wenn du nach Hause kommst, öffnest du normalerweise eine Tür. Das kannst du clever nutzen, um die Wahrscheinlichkeit weiter zu erhöhen:
Dadurch berücksichtigt der Sensor Türaktivität nur in den letzten zwei Minuten – perfekt für das Szenario „Nach Hause kommen“.
Live-Test & Feinabstimmung
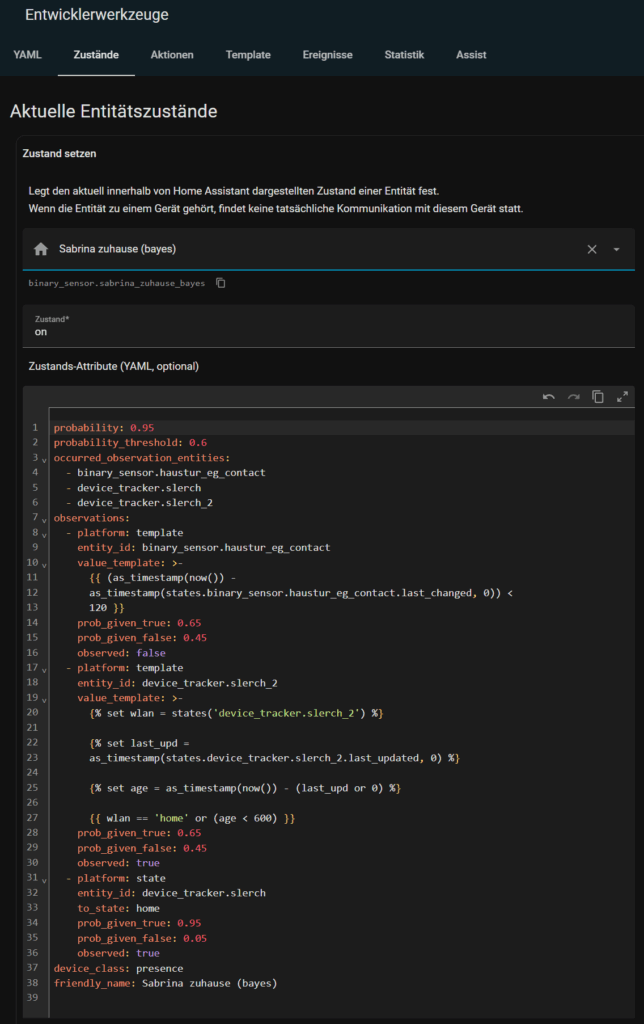
Nachdem du alles eingerichtet hast, kannst du den Zustand in den Entwicklerwerkzeugen prüfen. Die Entität zeigt dir:
Wenn du z. B. dein WLAN deaktivierst, sinkt der Wert leicht – bleibt aber über 0.6, solange andere Sensoren „Zuhause“ melden.
So erreichst du endlich ein stabiles Verhalten, auch bei kleinen Aussetzern.
Erweiterte Anwendungen
Der Bayesian Sensor kann weit mehr als nur Präsenzerkennung. Ein paar Ideen, wie du ihn nutzen kannst:
Nachtmodus aktivieren, wenn:
keine Bewegung mehr erkannt wird
alle Media Player aus sind
bestimmte Lichter aus sind
„Nicht zu Hause“-Modus, wenn:
niemand mehr aktiv ist
Tür längere Zeit geschlossen bleibt
Bewegungsmelder inaktiv sind
Dadurch erhältst du fließende Zustände, die viel realistischer wirken als reine Logik.
Kombination mit Automatisierungen
Du kannst den Bayesian Sensor wie jeden anderen Binärsensor in Automationen nutzen:
alias: Licht ausschalten bei Abwesenheit
trigger:
- platform: state
entity_id: binary_sensor.tobias_zuhauses_bayes
to: 'off'
action:
- service: light.turn_off
target:
area_id: wohnzimmer
Tipps für dein Setup
✅ Starte mit 2–3 Beobachtungen und erweitere schrittweise ✅ Teste Änderungen über die Entwicklerwerkzeuge ✅ Achte auf realistische Gewichtungen (WLAN nie zu hoch gewichten) ✅ Nutze Templates, um zeitbasierte Bedingungen (z. B. „letzte 10 Minuten“) einzubauen ✅ Lies die Wahrscheinlichkeiten aus und beobachte den Verlauf über ein paar Tage
Fazit – Warum der Bayesian Sensor so stark ist
Der Bayesian Sensor ist für mich einer der unterschätztesten, aber mächtigsten Sensoren in Home Assistant. Er ermöglicht eine flexible, menschlich anmutende Logik – ohne komplizierte Node-RED-Flows oder YAML-Monster.
Ich verwende ihn mittlerweile für:
Präsenzerkennung
Nachtmodus
Energiesteuerung (z. B. „Wahrscheinlichkeit, dass jemand gleich heimkommt“)
und Szenarien mit mehreren Personen
👉 Probiere es aus – du wirst schnell merken, wie stabil deine Automatisierungen werden.
Schreib mir gerne in die Kommentare, wofür du den Bayesian Sensor nutzt oder welche Kombinationen bei dir besonders gut funktionieren.